
遗传算法应用的性能调整
前言
在之前的文章里,我在一个项目中实现了一套基于遗传算法的题库智能组卷模块,因为这个是放在需要部署上线的网站应用里的,所以对模型的性能有一定要求,不仅需要考虑算法本身的一些技术实现问题,比如算法是否可以收敛,适应度函数的调整对于迭代次数的影响等等,还需要考虑到在业务功能中的性能问题,接口的时间损耗问题,遗传算法需要在适度的时间内尽早收敛得到相对满意的结果。不能用户点了一下,卡住半天没反应,就算能得出一个较为满意的结果,但使用体验也十分糟糕。
探索过程
在我最开始做完遗传算法代码的构建时,适应度函数的设置过于简单了,只用了难度系数这一个参数作为适应度函数的因子,并且题库中的题目数量也不够多,没有足够的数据支撑,导致种群的进化过早收敛,经常会刚初始化完种群就已经有满足预期的个体出现,如下图。

在发生该情况后,我对每个参数都进行逐个的调试,想要增加迭代的次数,并且探索各参数之间的关系及影响。基因变异概率,种群规模,选择规模,交叉概率,适应度期望值,迭代次数上限值等。
其中关于变异概率,如果增加基因变异的概率,即从原题目变异为满足条件的新题目,的确可以显著的增加迭代进化的次数,但仔细想想这样增加的迭代次数并没有什么实际的意义,很可能破坏原本迭代出的适应度高的目标试卷个体,只是一味的为了增加迭代次数而增加迭代次数,很快就放弃了这个方案。
调整种群规模的时候,发现过小的种群规模会导致比较难迭代进化出满足期望适应度的试卷个体,很容易就超过了迭代进化次数上限,并且因为规模小,一开始整个种群内的题目总数也少,交叉选择产生的新种群可能所有组合都根本满足不了期望适应度,更改迭代上限后迭代了6000多次也没有满足要求。过大的规模更是初始种群就已满足条件,没什么改观。
其他的参数都和变异概率与种群规模类似,要么没什么改观,要么就是一些有效果但没什么意义的改动。
最后仔细分析了一下问题所在,是因为适应度函数过于简单了,才导致了迭代过早收敛,然后对问题进行重新建模,设计了新的适应度函数,达到了预期效果。
最终结果
在对各种参数进行多轮测试的过程中,最终得到了一个较为满意,能协调好性能和迭代效果的模型。
相关参数:
- 初始种群数为12,变异概率为15%,
- 适应度期望值为0.97,锦标赛选择规模为0.6。
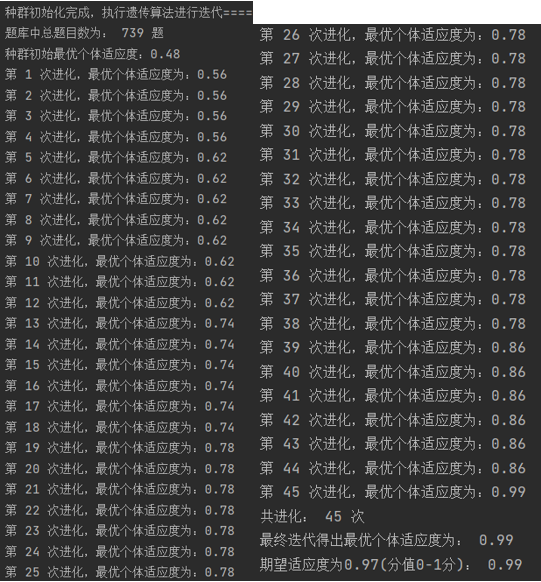
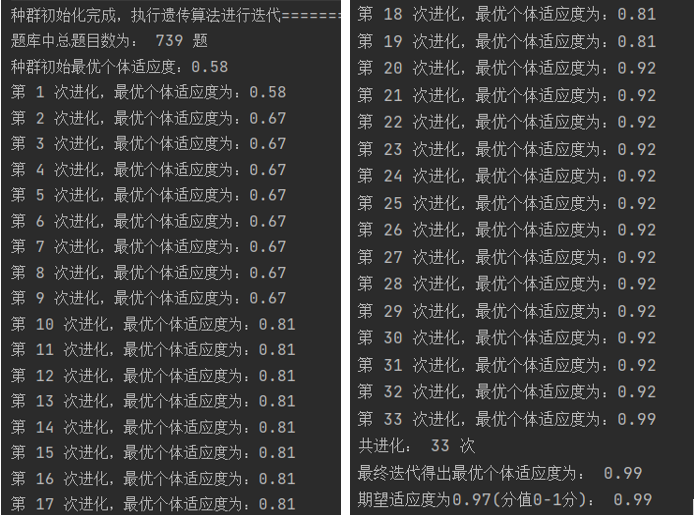
在进行的40轮遗传算法测试中,有一次初始种群的适应度就达到了0.99,其余大部分进化次数都在15-40次的区间内,有3轮超过了迭代最大次数上限60还未收敛到期望适应度内。
以上展示的是较为典型的几轮迭代进化,进化曲线较为平滑,因为我在迭代过程中保留了精英个体,即种群内适应度最高的个体。这样做有优点也有缺点,优点是可以使种群在适度范围内更早的收敛,更为稳定,并且即便未达到期望适应度就超过了迭代次数上限,也可以尽可能保留适应度最高的个体,即最满足需求的试卷个体,这样比较符合我对于遗传算法在该问题求解上的预期。缺点就是会影响种群在进化过程中的多样性,干涉了自然界中的基因遗传进化本质,会产生超级个体,使最终的解局部收敛,不满足整体预期。